
- يعمل الارتباط التشعبي بالكامل على الأجهزة المحلية، مما يحافظ على خصوصية كل عملية بحث
- يقوم التطبيق بفهرسة مجلدات البيانات الضخمة على أجهزة الكمبيوتر RTX في دقائق
- تتضاعف سرعة استنتاج LLM على Hyperlink مع أحدث تحسينات Nvidia
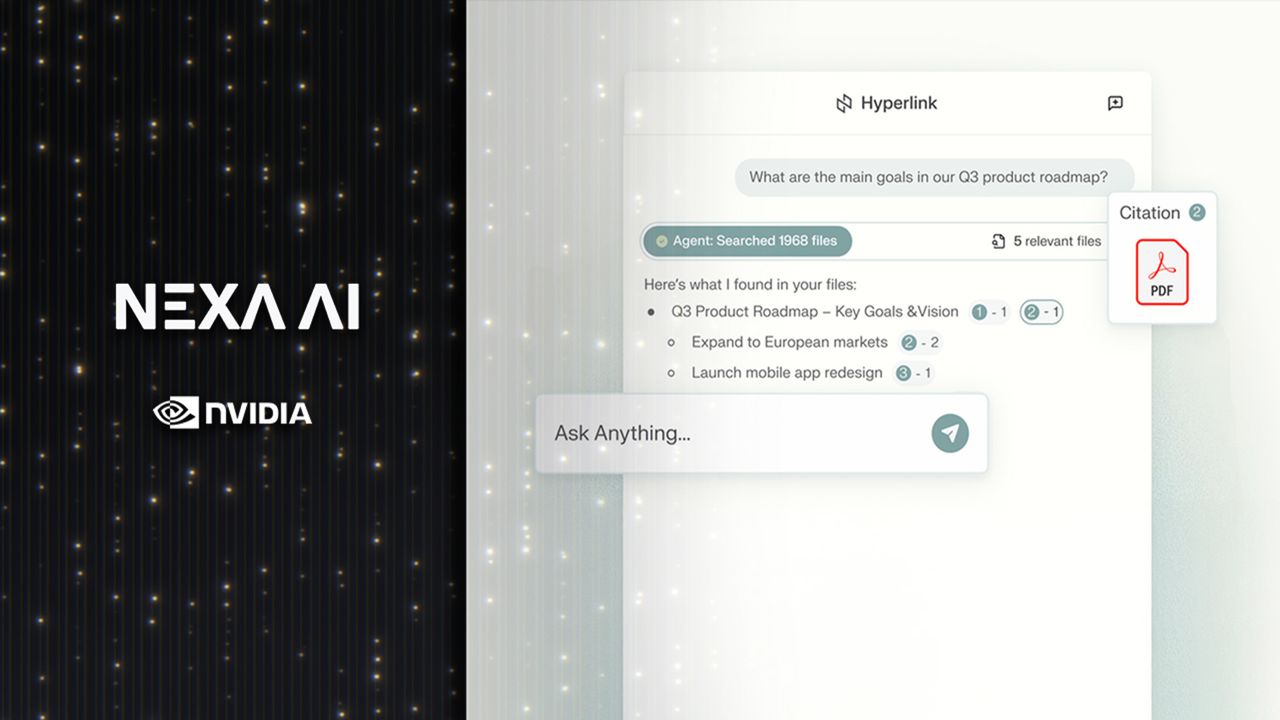
يقدم وكيل “Hyperlink” الجديد من Nexa.ai أسلوبًا للبحث في الذكاء الاصطناعي والذي يعمل بالكامل على الأجهزة المحلية.
تم تصميم التطبيق لأجهزة الكمبيوتر الشخصية Nvidia RTX AI، ويعمل كمساعد على الجهاز يحول البيانات الشخصية إلى رؤية منظمة.
أوضحت Nvidia كيف أنها بدلاً من إرسال الاستعلامات إلى خوادم بعيدة، تقوم بمعالجة كل شيء محليًا، مما يوفر السرعة والخصوصية.
الاستخبارات الخاصة بالسرعة المحلية
تم اختبار Hyperlink على نظام RTX 5090، حيث يقال إنه يوفر فهرسة أسرع بما يصل إلى 3x وسرعة استدلال نموذج اللغة الكبيرة 2x مقارنة بالإصدارات السابقة.
تشير هذه المقاييس إلى أنه يمكنه فحص آلاف الملفات وتنظيمها عبر جهاز كمبيوتر بكفاءة أكبر من معظم أدوات الذكاء الاصطناعي الموجودة.
الارتباط التشعبي لا يطابق مصطلحات البحث ببساطة، لأنه يفسر نية المستخدم من خلال تطبيق القدرات المنطقية لـ LLMs على الملفات المحلية، مما يسمح لها بتحديد موقع المواد ذات الصلة حتى عندما تكون أسماء الملفات غامضة أو غير مرتبطة بالمحتوى الفعلي.
يتماشى هذا التحول من البحث عن الكلمات الرئيسية الثابتة إلى الفهم السياقي مع التكامل المتزايد للذكاء الاصطناعي التوليدي في أدوات الإنتاجية اليومية.
يمكن للنظام أيضًا ربط الأفكار ذات الصلة من مستندات متعددة، وتقديم إجابات منظمة بمراجع واضحة.
على عكس معظم المساعدين السحابيين، يحتفظ Hyperlink بجميع بيانات المستخدم على الجهاز، وبالتالي فإن الملفات التي يقوم بمسحها ضوئيًا، بدءًا من ملفات PDF والشرائح إلى الصور، تظل خاصة، مما يضمن عدم مغادرة أي معلومات شخصية أو سرية للكمبيوتر.
يجذب هذا النموذج المتخصصين الذين يتعاملون مع البيانات الحساسة والذين ما زالوا يرغبون في الحصول على مزايا أداء الذكاء الاصطناعي التوليدي.
يمكن للمستخدمين الوصول إلى الاستجابات السياقية السريعة دون التعرض لخطر التعرض للبيانات المصاحبة للتخزين أو المعالجة عن بعد.
يمتد تحسين Nvidia لأجهزة RTX إلى ما هو أبعد من أداء البحث، حيث تدعي الشركة أن الجيل المعزز للاسترجاع (RAG) يقوم الآن بفهرسة مجلدات البيانات الكثيفة بشكل أسرع بما يصل إلى ثلاث مرات.
يمكن الآن فهرسة مجموعة نموذجية بحجم 1 غيغابايت كانت تستغرق ما يقرب من 15 دقيقة للمعالجة في حوالي 5 دقائق.
ويعني التحسن في سرعة الاستدلال أيضًا أن الاستجابات تظهر بسرعة أكبر، مما يجعل المهام اليومية مثل التحضير للاجتماعات أو جلسات الدراسة أو تحليل التقارير أكثر سلاسة.
يدمج الارتباط التشعبي الراحة مع التحكم من خلال الجمع بين التفكير المحلي وتسريع وحدة معالجة الرسومات، مما يجعله أداة ذكاء اصطناعي مفيدة للأشخاص الذين يرغبون في الحفاظ على خصوصية بياناتهم.
اتبع TechRadar على أخبار جوجل و أضفنا كمصدر مفضل للحصول على أخبار الخبراء والمراجعات والآراء في خلاصاتك. تأكد من النقر على زر المتابعة!
وبالطبع يمكنك أيضًا اتبع TechRadar على TikTok للحصول على الأخبار والمراجعات وفتح الصناديق في شكل فيديو، والحصول على تحديثات منتظمة منا على واتساب أيضاً.
التعليقات