
أعلنت Nvidia عن مزيد من التفاصيل حول وحدات المعالجة المركزية الجديدة لمركز بيانات Vera ذات 88 نواة في GTC 2026 هنا في سان خوسيه، كاليفورنيا، محققة مكاسب مذهلة في الأداء بنسبة 50٪ مقارنة بوحدات المعالجة المركزية القياسية، مدعومة بزيادة 1.5X في IPC من نوى Olympus والتصميم المبتكر عالي النطاق الترددي الذي تقول Nvidia إنه يوفر أسرع أداء أحادي الخيط في السوق. وكشفت الشركة أيضًا عن بنية Vera CPU Rack الجديدة، والتي تجمع 256 وحدة معالجة مركزية مبردة بالسوائل في حامل واحد لأحمال العمل المرتكزة على وحدة المعالجة المركزية، مما يحقق مكاسب بمقدار 6 أضعاف في إنتاجية وحدة المعالجة المركزية وضعف الأداء في أعباء عمل الذكاء الاصطناعي الوكيل.
يمثل تطور وحدة المعالجة المركزية Vera وتكاملها في الأنظمة ذات النطاق الحامل القابلة للنشر دخول Nvidia في مبيعات وحدة المعالجة المركزية المباشرة، مما يضع نفسها كمنافس لـ Intel وAMD في سوق وحدة المعالجة المركزية التقليدية. ناهيك عن التنافس ضد النكهات العديدة لمعالجات Arm المخصصة التي يستخدمها أكبر المقياس الفائق في العالم. وهذا لا يشكل مفاجأة كاملة، حيث يأتي في أعقاب إعلان الشركة عن ذلك ستقوم Meta الآن بنشر أجيال متعددة من أنظمة Nvidia CPU فقط عبر بنيتها التحتية. ستواصل Nvidia أيضًا استخدام وحدات المعالجة المركزية (CPUs) لأنظمتها الخاصة التي تركز على وحدة معالجة الرسومات (GPU)، مثل منصة Vera Rubin التي تناولناها بتعمق أكثر هنا.
يستمر المقال أدناه
مواصفات وأداء وحدة المعالجة المركزية Nvidia Vera
صممت Nvidia وحدة المعالجة المركزية Vera لتوفير الأفضل في العديد من العوالم، بهدف دمج الأعداد الأساسية العالية لوحدات المعالجة المركزية السحابية واسعة النطاق مع الأداء العالي أحادي الخيط لوحدات المعالجة المركزية للألعاب وكفاءة الطاقة لشرائح الهاتف المحمول، كل ذلك بهدف تسريع المهام الشائعة التي تعتمد على وحدة معالجة الرسومات في الذكاء الاصطناعي الوكيل، وأحمال عمل التدريب والاستدلال، مثل تنفيذ Python واستعلامات SQL وتجميع التعليمات البرمجية.
أخيرًا، تطالب Nvidia بأداء 1.5x لكل صندوق حماية مقارنة بمنافسيها x86، و3x عرض النطاق الترددي للذاكرة لكل نواة، وضعف الكفاءة. ولتحقيق هذه الأهداف، صممت الشركة وحدة معالجة مركزية ذات 88 نواة و144 نواة، وهي زيادة عن الجيل الأول من معالجات Grace البالغ عددها 72 نواة. تدعي Nvidia أيضًا أن النوى توفر تحسينًا بمقدار 1.5X في إنتاجية التعليمات لكل دورة (IPC)، وهي قفزة هائلة بين الأجيال مقارنةً بالبنى المنافسة الأخرى، والتي تميل إلى الحصول على زيادة برقم واحد أو نسبة منخفضة من المراهقين مع كل جيل. مع الجيل السابق من Grace، استخدمت Nvidia نوى Arm Neoverse الجاهزة، لكن الشركة تنص على أن نوى Olympus الجديدة الموجودة في Vera هي “مصممة من قبل Nvidia”، مما يشير إلى أن الشركة أجرت تعديلات مخصصة على التصميم المرجعي.
تتميز نوى Arm v9.2-A Olympus بتعدد الخيوط المكانية، والتي تعزل فعليًا المكونات المختلفة لخط الأنابيب عن طريق عدم تقسيم العناصر الرئيسية إلى شرائح زمنية، مثل وحدات التنفيذ وذاكرة التخزين المؤقت وملفات التسجيل، مع تشغيل الخيط الآخر على نفس النواة. يتناقض هذا مع تقسيم الوقت القياسي الموجود في تطبيقات أخرى متزامنة متعددة الخيوط (SMT)، وهي عملية تجعل الخيوط تتناوب باستخدام الموارد. تعمل مؤشرات الترابط المكانية المتعددة على زيادة توازي مستوى التعليمات (ILP) والإنتاجية وإمكانية التنبؤ بالأداء عن طريق سحب التعليمات من سلاسل رسائل أخرى عندما تكون عناصر التنفيذ خاملة، وبالتالي ضمان الاستخدام الكامل.
في الواقع، يسمح هذا لكلا الخيطين بالعمل في وقت واحد على نواة واحدة، بينما في تطبيق SMT القياسي، تتناوب الخيوط بشكل أساسي على نواة واحدة. وبطبيعة الحال، سيكون هذا بمثابة نعمة للبيئات متعددة الإيجارات.

تقوم Nvidia بترتيب جميع النوى الـ 88 في مجال واحد، لذلك لا توجد غرابة مركزية في NUMA محفزة لزمن الوصول، في تناقض صارخ مع المنافسين الحاليين ذوي العدد العالي من النوى x86. وهذا له آثار كبيرة على زمن الوصول والقدرة على التنبؤ وعرض النطاق الترددي وسهولة البرمجة. لم تشارك الشركة التفاصيل الكاملة لكيفية إنجاز هذا العمل الفذ مع الحفاظ على زمن الوصول المناسب لكل نواة، لكن الشريحة تتميز بجيل جديد من Nvidia Scalable Coherency Fabric (SCF)، وهي طوبولوجيا شبكية مبنية من Arm's شبكة شبكية متماسكة CMN-700 تستخدم في نوى ذراع جريس نيوفيرس. انتقلت شركة Arm إلى شبكة Neoverse CMN S3 الأحدث بأحدث تصميماتها، ومن المحتمل أن تستخدم Vera هذا التصميم أو أحد أشكاله المختلفة.
يمكن للشبكة المتداخلة توفير إنتاجية مذهلة للذاكرة إلى النوى بشكل إجمالي، بل وأكثر من ذلك عندما تكون بعض النوى أكثر جوعًا لعرض النطاق الترددي من غيرها. دعمت Grace 546 جيجابايت/ثانية من إنتاجية الذاكرة للشبكة، بمعدل 7.6 جيجابايت/ثانية لكل نواة. قامت Vera بمضاعفة ذلك إلى 1.2 تيرابايت/ثانية من عرض النطاق الترددي الذي يتم تغذيته بواسطة 1.5 تيرابايت من وحدات SOCAMM LPPDDR5 (زيادة في السعة 3x)، والتي تصل إلى متوسط 13.6 جيجابايت/ثانية لكل نواة في ظروف التحميل الكامل. والأهم من ذلك، أن البنية تدعم الآن ما يصل إلى 80 جيجابايت/ثانية من الإنتاجية لأي نواة واحدة عندما لا تكون ظروف التحميل متسقة عبر الشبكة، وهو ما يمثل زيادة مذهلة للخيوط المتعطشة لعرض النطاق الترددي.
يتضمن مسار التنفيذ وحدة فك تشفير التعليمات بعرض 10، وأداة تنبؤ للفرع العصبي تدعم تنبؤين فرعيين لكل دورة، ومحرك جلب مسبق لتحليلات قاعدة بيانات الرسم البياني المخصص، ومخزن مؤقت للتعليمات محسّن بواسطة PyTorch.
تدعم الشريحة بشكل كامل الحوسبة السرية، وهو تقدم ملحوظ مقارنة بـ Grace الذي يسمح بنطاقات CPU+GPU المحمية بالكامل. تتميز وحدة المعالجة المركزية أيضًا بواجهة NVLink-C2C مع ما يصل إلى 1.8 تيرابايت/ثانية من الإنتاجية، وهو ضعف الاتصال البيني لـ Grace الذي يبلغ 900 جيجابايت/ثانية وأسرع سبع مرات من PCIe 6.0. كما أنه يدعم تكوينات المعالجين (2P).
بشكل عام، تدعم Vera المجموعة الكاملة من التقنيات المتوقعة من معالج مركز البيانات الحديث، بما في ذلك دعم PCIe 6.0 وCXL 3.1، ولكن مع عرض النطاق الترددي وتصميم حوسبة يركز على زمن الوصول مما يجعله جيدًا بشكل فريد للاستخدام في سير عمل الذكاء الاصطناعي.
حامل وحدة المعالجة المركزية Vera والأداء المعياري
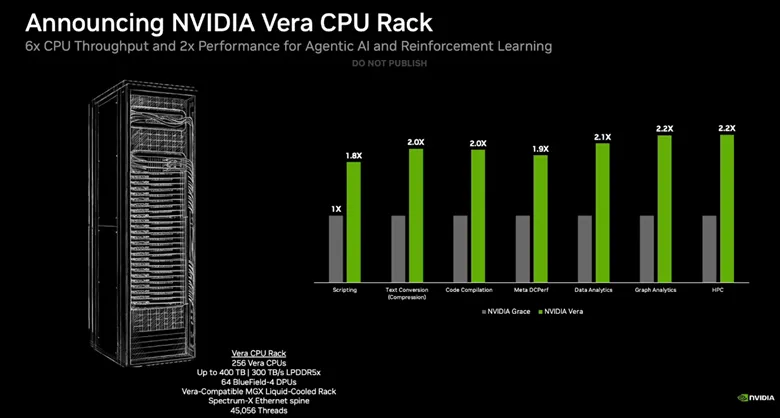
لقد كانت النعمة بالفعل بمثابة لبنة أساسية في العديد من الأشياء أنظمة Nvidia GPU+CPU، مشتمل بعض من أسرع أجهزة الكمبيوتر العملاقة العاملة بالذكاء الاصطناعي على هذا الكوكب، لكن هدف Nvidia الموسع هو الاستفادة من Vera في رفوف وحدة المعالجة المركزية (CPU) التي يمكن نشرها على نطاق أوسع.
يحقق حامل وحدة المعالجة المركزية Vera هذا الهدف من خلال 256 وحدة معالجة مركزية Vera مبردة بالسوائل مقترنة بـ 74 وحدة DPU Bluefield-4 وشبكة ConnectX SuperNIC. يزن الحامل ما يصل إلى 400 تيرابايت من LPDDR5 و300 تيرابايت/ثانية من إنتاجية الذاكرة الإجمالية. يعمل ذلك على تغذية 45.056 سلسلة، والتي تقول Nvidia إنها تدعم 22.500 بيئة متزامنة لوحدة المعالجة المركزية تعمل بشكل مستقل.
شاركت Nvidia المعايير في مجموعة واسعة من أعباء العمل، حيث روجت لتحسين الأداء من 1.8x إلى 2.2x مقارنة بـ Grace في البرمجة النصية، والتجميع، وتحليلات البيانات، وتحليلات الرسوم البيانية، وأحمال عمل HPC، من بين أمور أخرى.
من الطبيعي أن يتوقع المرء أن يتم نشر هذا النظام في شركة Meta، التي أعلنت مؤخرًا عن شراكتها مع Nvidia لأنظمة وحدة المعالجة المركزية فقط، لكن Nvidia تقول إنها ستقدم أيضًا نظام حامل وحدة المعالجة المركزية Vera إلى المتوسعين الفائقين، بما في ذلك Oracle وCoreweave وNebius وAlibaba وغيرها.
ستوفر مجموعة واسعة من مصنعي المعدات الأصلية (OEM) ومصنعي التصميم الأصلي (ODM) أيضًا خوادم أحادية وثنائية المقبس للسوق الأوسع لمجموعة واسعة من حالات الاستخدام، بما في ذلك الشركات ذات الوزن الثقيل في الصناعة مثل Dell وHPE وLenovo وSupermicro وFoxconn وغيرها الكثير. سيتم أيضًا استخدام وحدات المعالجة المركزية Vera لأنظمة Nvidia HGX NVL8.
ولعل الأهم من ذلك هو أن هذه الرفوف ستعمل أيضًا كجزء لا يتجزأ من منصة Vera Rubin الأوسع من Nvidia، والتي تتميز بسبع شرائح في المجموع، بما في ذلك Rubin GPU، وNVLink6 Switch للتوصيل البيني على نطاق الحامل، وConnectX-9 SuperNIC للشبكات، وBluefield 4 DPU، وSpectrum-X 102.4T Co-packed Optics Switch، وGroq 3 LPUs من Nvidia.
أصبحت وحدات المعالجة المركزية Vera في مرحلة الإنتاج الكامل الآن ومن المقرر أن يتم تسليمها بدءًا من النصف الثاني من هذا العام.

يتبع أجهزة توم على أخبار جوجل، أو أضفنا كمصدر مفضل، للحصول على آخر الأخبار والتحليلات والمراجعات في خلاصاتك.
التعليقات